This week featured an interesting story in which MSNBC host Joy Reid was called out over homophobic posts attributed to her political blog, The Reid Report, in the late-2000s. Reid had previously apologized for similar posts identified late last year, but when a new tranche of homophobic posts were identified last week by a Twitter user who found the since-deleted posts through the Internet Archive's Wayback Machine, Reid denied authoring the posts and claimed they were fabricated. Subsequent reporting in The Daily Beast found that details provided by Reid's cybersecurity consultant to deny the posts' authenticity did not hold up to scrutiny. (The Wayback Machine is an excellent researcher's resource that we've written about several times.) There are several fascinating elements to this story with important implications for how the Internet Archive's Wayback Machine, and a complementary system called archive.today, can be used when documenting a since-deleted website:
In December, following the public reveal of the first tranche of homophobic blog posts which Reid apologized for, lawyers for Reid contacted the Internet Archive asking the site take down the archived version of the site, claiming that "fraudulent" posts had been inserted among the "legitimate content" in the archived blog. The Internet Archive conducted a review which found no tampering or hacking of the Wayback Machine's archive of the blog, and declined to remove the archived website "due to Reid’s being a journalist (a very high-profile one, at that) and the journalistic nature of the blog archives."
Then in February and March the live website for Reid's blog was updated to add a robots.txt file to specifically block the Wayback Machine from archiving the site, triggering an automated policy of the Internet Archive which retroactively removed (or at least blocked from public view) their archived versions of the blog. That robots.txt file then disappeared and reappeared several times, suggesting that the archived site may have been intermittently available again.
The Daily Beast article is interesting in this context, because that article knocked down claims by Reid's cybersecurity consultant Jonathan Nichols, who alleged that several of the posts were fabricated because they didn't appear in the Wayback Machine. The Daily Beast refuted these claims by findings those disputed posts in the archive, however the links provided in the article currently will not display due to the robots.txt policy.
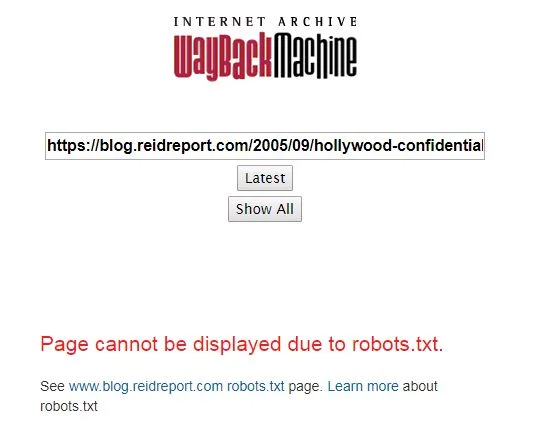
As the archived page appeared in the Wayback Machine on April 27, 2018
Either The Daily Beast wrote their findings at a time when the archived website was intermittently available, or possibly it relied on a secondary website archive service, archive.today, for a capture of the Wayback Machine's capture of the original blog post.
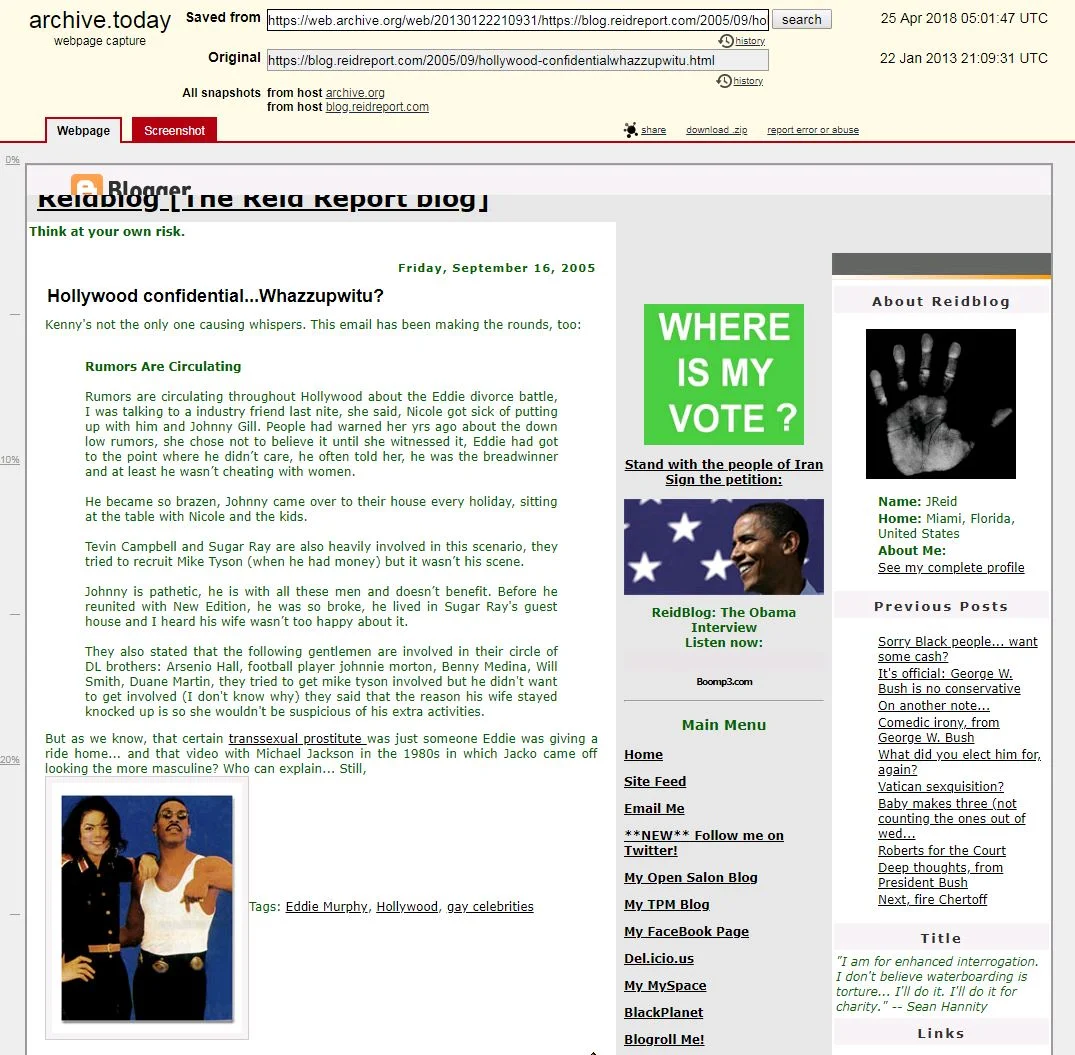
The same link now unavailable on Wayback Machine, as saved by archive.today
Indeed a number of those since-deleted blog posts remain available via the archive.today system. Archive.today is an interesting complementary resource to the Wayback Machine which allows for users to request a specific web page be archived, as opposed to the Wayback Machine's automated web crawling system. Since the request to archive a page on archive.today is initiated by an individual user, it isn't limited by a website's robots.txt exclusion, and also the archive.today policy is to not remove archived pages by request. So it is a potentially useful service to capture a copy of a web page that you expect may be deleted in the future, since as the Reid blog saga demonstrates, there are circumstances in which the Wayback Machine can't be relied on as a permanent resource when a domain owner wants their archived version removed.